
디지털사회 제48호: 허위정보는 어떻게 전파되는가?
작성자
ssk
작성일
2023-06-29 16:01
조회
1586
허위정보는 어떻게 전파되는가? 시뮬레이션으로 알아보는 허위정보 네트워크
이병재(연세대학교 디지털사회과학센터)
초연결된 네트워크 사회의 현상들은 매우 복잡하게 연결되어 있으며 몇 가지 주요 요인만으로 이 현상들을 설명하는 것은 점점 더 어려워지고 있다. 또한, 네트워크 사회의 특징은 구성원들간의 끊임없는 상호작용이며, 이 상호작용의 결과가 개인들에게 다시 영향을 미치기 때문에 기존의 결정론적, 연역적 모델에 의한 설명에는 많은 어려움이 있다. 날로 복잡해지는 사회현상 연구를 위하여 새로운 이론체계와 연구도구에 대한 필요성이 증가하고 있는데, 복잡계 이론에 기반한 시뮬레이션은 실제적 도움을 줄 수 있다.
복잡계 이론(complexity theory)은 최근에 등장한 새로운 이론은 아니다. 복잡계 이론은 카오스 이론에 기반하여 자연의 복잡성을 연구하며, 1970년대 이후 폭발적으로 성장해 온 비평형계 과학과 카오스이론에 그 뿌리를 두고 있다. 초기의 복잡계 연구는 고전역학으로 대변되는 결정론적 세계관과 20세기 초에 크게 발전한 양자역학 및 통계역학에 기초한 확률론적 세계관 사이의 내재적 갈등구조를 해결하려는 시도에서 시작되었다. 복잡계 이론을 사회과학에 적용하는 것은 복잡하고 이해하기 힘든 사회현상을 체계적으로 이해하려는 노력의 일환인데, 복잡계 이론은 단일한 학문분야의 고유한 이론체계가 아니라 다양한 학문분야의 접근방식을 포함하고 있다(Page 2010; Miller and Page 2014; Byrne and Callaghan 2022).
사회과학에서 복잡계 이론의 기본 시각은 세상이 수많은 구성요소로 이루어져 있고, 그 수많은 구성요소가 끊임없이 상호작용한다는 인식론이 바탕을 이루고 있다. 사회현상은 많은 구성요소들 사이의 상호작용의 결과이며, 상호작용의 결과 긍정적, 부정적 피드백이 발생하여 환류한다는 것이다. 복잡계 이론은 네트워크 사회로 대표되는 현대 사회의 현상들, 특히 사이버공간에서 나타나는 여러 가지 현상들을 이해하는데 유용하다.
복잡계 과학의 연구방법으로 널리 사용되는 것이 행위자 기반 모델(Agent-based modeling)이다(Epstein 1996, 2006, 2014). 일반적으로 행위자 기반 모델을 적용한 연구는 행위자의 행동과 상호작용이 거시적인 차원에서의 시스템의 창발을 가져올 수 있다는 전제 위에서, 먼저 거시적 수준에서 정형화된 사실을 제시한 다음, 미시적 수준에서 행위자의 행동을 통해 거시적 수준의 정형화된 사실이 일어나는 과정을 재현하는 방식으로 진행된다. 이렇게 미시와 거시를 연결하는 접근은 개인, 지역, 국가 등 여러 수준에 걸쳐 적용될 수 있다. 어떤 현상이 일어나는 과정에 대한 이론이 정립되어 있는 경우 행위자 기반 모델은 해당 이론을 적용해서 현상을 예측하는 용도로 사용될 수도 있고, 어떤 현상이 일어나는 과정에 대한 이해가 부족한 경우 행위자 기반 모델은 이론을 생성하고 정교화하는 용도로 활용될 수도 있다. 연구자들은 모델의 변수값을 조절하면서 시뮬레이션을 반복해서 수행할 수 있는데. 실제 실험이나 현장연구에서 이런 변수값 조절과 반복 테스트는 불가하다. 시뮬레이션을 통해 반사실적 분석(counterfactual analysis)을 수행할 수도 있는데, 이런 분석을 통해 변수값이 흔히 관찰되는 범위를 넘어서는 극단적인 경우를 시뮬레이션할 수도 있다.
행위자 기반 모델은 코로나-19와 같은 전염병의 전파 및 백신 접종의 효과에 대한 예측은 물론 다양한 정책 도입의 효과를 예측하는 데도 널리 사용되어 왔다. 이러한 연구들은 주요 행위자를 식별하고, 이 행위자들의 행동규칙을 모델링하는 것에 초점을 맞추고 있다. 행위자 기반 규칙을 구현하기 위해 행위자를 정의하는 것이 중요하지만, 이 밖에도 행위의 대상과 행위가 이루어지는 맥락의 모델링이 중요하다. 행위자 기반 모델링의 가장 핵심적인 구성요소는 행위자(agent)이다. 각 행위자는 상이한 능력, 경험, 인지패턴을 가지고 있으며, 이러한 능력, 경험, 인지패턴은 시간의 흐름에 따라 행위자가 환경에 적응하는 데 활용될 수 있다. 행위자 기반 모델의 또 다른 구성요소는 조건이다. 조건은 특정 사회의 규범이나 제도를 지칭하는데 행위자의 행동이 이 제약하에서 이루어진다는 의미에서 중요한 변수이다. 이어서 다음 절에서는 간단한 행위자 기반 모형을 통해 허위정보 전파의 시뮬레이션 결과를 소개한다.
Netlogo를 활용한 허위정보 전파 시뮬레이션
이 시뮬레이션 모델에서 행위자는 지식의 수준에 따른 두 개의 집단과 별도의 음모론 신봉 집단으로 구성되어 있다고 설정된다. 여기서 지식은 반드시 특정 분야의 전문지식만을 말하는 것은 아니며 전반적인 문해력을 지칭한다. 문해력에는 미디어나 특히 SNS를 통해 접한 뉴스에 대해서 검색과 숙고를 통해서 확인하는 능력이 포함된다(이 부분에 대해서는 연세대학교 디지털사회과학센터(http://cdss.yonsei.ac.kr)의 “가짜뉴스 판별법 12조”를 참조). 우선 2개의 집단은 문해력을 기준으로 문해력이 높은 집단과 낮은 집단으로 나누어지며, 세 번째 집단인 “음모론 신봉집단”은 과학적인 지식을 믿지 않으며 정부나 과학자에 대한 음모론을 신뢰하는 집단이다. 이 게임의 모든 구성원들은 이 세 집단 중 하나에 속한 상태에서 시작되며, 주변의 사람들과 상호작용을 한다. 각 구성원의 위치는 무작위로 배정되기 때문에 주변의 사람들은 자신과 같은 집단일수도, 다른 집단일 수도 있다.
허위정보 전파에 영향을 미치는 조건들은 정보의 질과 전파 매체들과 관련된다. 첫 번째는 정보의 실현 가능성으로, 해당 정보가 사람들에게 그럴 듯하게 들릴 0~1 사이의 확률이다(0에 가까울수록 황당하며, 1에 가까울수록 그럴 듯함). 황당하게 들릴수록 허위정보의 전달 가능성은 낮아지며, 그럴 듯할수록 높아진다. 두 번째는 정보의 전달 방식이다. 해당 정보가 얼마나 신빙성 있게 가공되어 전달되는가이며, 이 역시 0~1 사이의 확률로 표시된다. 0에 가까울수록 허위임을 알아보기 쉬운 방식으로, 1에 가까울수록 그럴 듯하게 포장되어 전달된다. 세 번째 조건은 얼마나 많은 미디어에서 해당 정보를 보도하였는가를 나타내며, 역시 0~1의 확률로 표시된다(0에 가까울수록 적게 보도, 1에 가까울수록 많이 보도). 많은 미디어에서 보도될수록 해당 허위정보가 전파될 가능성은 높아진다.
이러한 조건 하에서 위의 세 집단 중 하나에 속한 개인들은 주변의 사람들과 끊임없이 접촉한다. 이 시뮬레이션을 통해 보여주고자 하는 것은 상이한 문해력 수준을 가진 사람들로 구성된 사회에서 허위정보가 유통되었을 때 어느 정도로 빠르게 그 사회의 구성원들이 허위정보를 신뢰하게 되는가이다.
시뮬레이션의 기본 절차
다음으로 설정하는 것은 행위자 간의 상호작용의 결과로 발생하는 해당 정보에 대한 신뢰도의 변화이다. 무작위로 한 명을 선택하여 보자. 이 행위자는 주변의 다른 행위자 한 명과 상호작용을 한다. 저(低)문해력 집단에 속하는 행위자 1이 다른 행위자(행위자 2)를 만날 경우, 양자간에 의견이 다르면 행위자 2의 의견으로 바뀐다. 이 경우, 행위자 2가 저문해력 집단인가, 고(高)문해력 집단인가는 중요하지 않다. 만약 행위자 1과 행위자 2 모두 고문해력 집단에 속하는 경우, 행위자 1은 행위자의 2의 허위정보에 대한 태도가 자신의 태도와 다를 경우에만 태도를 바꾸게 된다. 즉, 고문해력 행위자 1이 허위정보를 믿고 있고, 고문해력 행위자 2는 그렇지 않다면 행위자 1도 허위정보를 믿지 않는 방향으로 바뀌게 된다. 만약 둘 다 허위정보를 믿고 있었다면 태도의 변화는 없다. 그리고 고문해력 행위자 1은 허위정보를 믿지 않고 있고, 고문해력 행위자 2는 허위정보를 믿고 있다면, 행위자 1의 태도는 다른 조건들(허위 정보에 관한 3가지 조건들)에 영향에 따라 변화할 수도, 변화하지 않을 수도 있다. 마지막으로 행위자 1이 음모론 신봉자들인 경우이다. 음모론 신봉자들은 과학적 지식이나 고문해력 집단을 신뢰하지 않는 사람들이다(하지만, 이들은 허위정보를 믿을 수도 있고 그렇지 않을 수도 있다). 이 경우 행위자 1은 접촉하는 행위자 2가 저문해력 집단일 때, 그리고 자신과 의견(허위정보에 대한 태도)이 다를 때만 의견을 바꾼다.
다음은 이상의 간단한 조건들 하에서 실시한 시뮬레이션 결과이다. 아래의 시뮬레이션에서 첫째 사회는 고문해력 집단 10%, 저문해력 집단 80%, 그리고 음모론자 10%인 사회이다(저문해력 사회). 둘째는 고문해력 집단 35%, 저문해력 집단 55%, 음모론자 10%인 사회이다(중간 문해력 사회), 세 번째는 고문해력 집단 80%, 저문해력 집단 10%, 음모론자 10%인 사회이다(고문해력 사회). 그리고 허위정보 전파에 영향을 미치는 조건들의 값이 0.1, 0.5, 0.9인 상황을 설정하였다. 0.1인 상황은 허위정보가 생산되기는 하지만, 설득력이 매우 낮고 신빙성 없는 방식으로 보도되고 미디어에서 거의 다루어지지 않는 경우이다. 0.9인 상황은 허위정보이지만, 설득력이 매우 높고, 신빙성 있는 방식으로 뉴스 형태로 보도되고, 거의 모든 미디어에서 보도되는 경우이다. 이상의 조건들을 결합하여 9가지의 시나리오를 생성하였다. 아래의 결과는 500명의 행위자들을 대상으로 500회의 시뮬레이션을 실시한 후 각 사회에서 해당 허위정보를 믿는 사람과 믿지 않은 사람들의 숫자를 그래프로 나타낸 것이다.
<그림 1> 9개 시나리오 시뮬레이션 결과
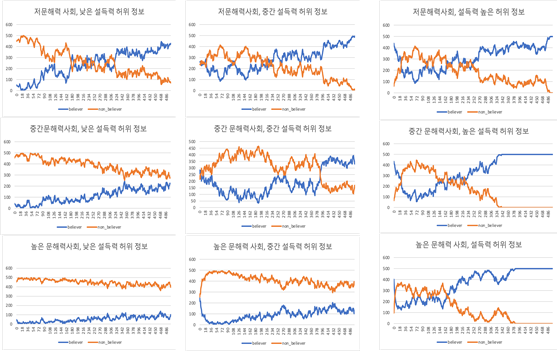
맨 윗줄의 결과는 전체적으로 문해력이 높은 사람의 비율이 많지 않은 사회에서 어느 정도의 시간이 지나면 허위정보의 설득력과 별 상관없이 허위정보를 믿는 사람들이 증가하는 것을 보여준다. 중간 열의 결과는 중간 문해력 사회, 즉 현실에 가장 가까운 사회의 경우, 허위정보가 제시되는 방식에 따라 커다란 영향을 받는다. 허위정보가 설득력이 약한 방식으로 제시되는 경우 시뮬레이션의 마지막 시점까지 허위정보를 신뢰하지 않는 인구가 더 많았다. 하지만, 신뢰하는 인구와 그렇지 않은 인구의 수는 근접하고 있다. 허위 뉴스의 설득력이 중간 정도인 경우 상당한 경쟁관계에 있음을 보여준다. 시간의 경과에 따라 허위 뉴스를 믿는 사람과 그렇지 않은 사람의 수는 등락을 거듭하지만, 결국은 믿는 사람이 늘어남을 보여준다. 허위정보가 설득력 있게 제시되는 경우에는 초기에는 신뢰하지 않지만, 결국은 믿는 사람이 늘어나는 것을 보여준다. 마지막으로 문해력이 높은 사회에서는 허위정보가 설득력 없게 제시되거나 중간 정도로 제시될 때에는 허위정보를 믿지 않는 사람이 매우 높게 나타난다. 하지만, 설득력 있는 방식으로 그럴 듯한 뉴스를 지속적으로 거의 모든 미디어에서 보도하는 경우 믿는 사람의 숫자가 늘어난다.
이상으로 Netlogo라는 시뮬레이션 프로그램을 활용하여 몇 개의 간단한 변수들과 환경 조건들을 설정하여 다양한 시나리오를 통해 시간에 따른 허위정보의 유포과정을 살펴보았다. 앞서 말한 바와 같이 시뮬레이션 결과는 기본 설정의 미세한 차이가 커다란 결과의 차이를 가져올 수 있다. 따라서 본 시뮬레이션의 기본 설정의 미세한 변경으로 전혀 다른 결과를 산출할 가능성도 존재한다. 하지만, 이 시뮬레이션은 한 사회의 문해력 있는 인구의 비율과 미디어의 역할이 허위정보 유포에 미치는 영향을 잘 보여준다고 할 수 있다. 문해력 있는 인구의 비율이 충분히 높은 사회에서는, 마치 바이러스로부터의 집단면역처럼 허위정보에 대한 면역력을 사회 전체가 가질 수 있다. 반면, 9번째 시나리오의 시뮬레이션 결과는 우리 사회가 미래에 경험할 수 있는 극단적인 상황에서 대해서도 통찰을 제공한다. 아무리 사회의 평균적인 문해력이 충분히 높더라도, 허위정보가 설득력 있는 방식으로 모든 공신력 있는 매체에서 제공되는 상황에서는 허위정보에 의한 사회의 침식이 가능하다는 것이다.
나가며
행위자 중심 모델링을 비롯한 시뮬레이션 분석은 현실을 지나치게 단순화하며 검증되지 않은 전제에 의존하고 있다는 비판을 받기도 한다. 그러나 모델을 지나치게 복잡하게 만들면 계산의 복잡함과 더불어 함의를 찾기 어렵다는 단점이 있다. 이런 의미에서 통계학자인 Box가 한 말인 “모든 모델은 틀렸다. 하지만 어떤 모델들은 유용하다(All models are wrong, but some are useful)”는 시뮬레이션에도 적용된다. 중요한 변수 및 조건들에 대한 설정과 다양한 조작을 통해 다양한 결과를 예측해 볼 수 있다는 점에서 시뮬레이션은 많은 장점이 있으며, 컴퓨터의 발달로 인해 더욱 복잡한, 현실적인 시뮬레이션이 가능해지고 있다. 글에서 제시한 허위정보의 경우도 수백만의 행위자와 트롤, 봇, 가짜뉴스 생산자, 정파성 등을 포함하는 시뮬레이션을 실시해볼 수 있는 세상이 되었다. 특히나 사회의 중요 정책을 결정하는 데 있어 정책의 기대효과에 대해 고민하는 정책결정자들에게 시뮬레이션은 좋은 도구가 될 수 있다.
<참고문헌 및 시뮬레이션 소프트웨어>
1. 참고문헌
Byrne, David and Gillian Callaghan. 2022. Complexity Theory and the Social Science: the State of the Art. 2nd ed. London: Routledge.
Epstein, Joshua. 1996. Growing Artificial Societies: Social Science from the Bottom Up. Washington, DC: Brookings Institution.
Epstein, Joshua. 2006. Generative Social Science: Studies in Agent-Based Computational Modeling. Princeton: Princeton University Press.
Epstein, Joshua. 2014. Agent_zero: Toward Neurocognitive Foundations for Generative Social Science. Princeton: Princeton University Press.
Miller, John and Scott Page, Complex Adaptive Systems: An Introduction to Computational Models of Social Life. Princeton, NJ: Princeton University Press. 2009.
Holland, John. Signals and Boundaries: Building Blocks for Complex Adaptive Systems.
Waldrop, M. Mitchell. Complexity: The Emerging Science at the Edge of Order and Chaos.
Downey, Allen. 2018. Think Complexity: Complexity Science and Computational Modeling. 2nd ed. Boston, MA: O’Reilley.
Page, Scott. 2010. Diversity and Complexity. Princeton, NJ: Princeton University Press.
2. Simulation Softwares
1) Netlogo (https://ccl.northwestern.edu/netlogo/)
2) repast (https://repast.github.io/)
디지털사회(Digital Society)는 연세대학교 디지털사회과학센터(Center for Digital Social Science)에서 발행하는 이슈브리프입니다. 디지털사회의 내용은 저자 개인의 견해이며, 디지털사회과학센터의 공식입장이 아님을 밝힙니다.
전체 0
댓글을 남기려면 로그인하세요.