
디지털사회 제36호: 알고리즘 공개에 관하여
작성자
ssk
작성일
2021-10-20 08:32
조회
4953
알고리즘 공개에 관하여
모정훈 (연세대학교 산업공학과 교수)
들어가며디지털 플랫폼이 일상에 미치는 영향이 커지면서 이 플랫폼의 작동절차인 “알고리즘”이 이슈가 되고 있다. “문제 해결을 위한 일련의 절차 또는 방법”인 알고리즘 (Algorithm)이라는 공학용어를 다양한 매체에서 접할 수 있게 된 것은 알고리즘이 우리 일상에 미치는 영향이 커졌음을 보여준다. 구글과 네이버로 정보를 검색하고, 포털에서 뉴스를 보고, 쿠팡에서 상품과 음식을 주문할 때 우리는 플랫폼의 검색 알고리즘, 뉴스 편집 알고리즘, 쿠팡맨 배송 알고리즘을 사용한다.
플랫폼의 검색 알고리즘, 뉴스 편집 알고리즘, 상품 거래에 관한 알고리즘 등을 공개하라는 입법안과 개정안들이 발의되었다. [표 1]과 [표 2]는 최근 발의된 입법안 개정안 등을 보여준다. 올해 1월, 공정거래위원회는 “온라인 플랫폼 공정화법”을 국회에 제출하였고, 그 법안을 통해 온라인 플랫폼 중개거래계약을 체결할 때 거래되는 재화나 서비스가 노출되는 순서와 기준, 수수료와 광고비가 노출 순서에 미치는 영향 등을 서면으로 교부하도록 하였다. 또, 전자상거래법 개정안에는 온라인 쇼핑플랫폼을 대상으로 상품의 검색 결과 순위를 결정하는 주요 기준을 공개하도록 하였고 신문법 개정안은 인터넷 뉴스사업자의 기사배열의 기본 방침 및 구체적 기준을 공개하도록 하였다. 또, 정보통신망법 개정안에는 정보통신서비스 제공자의 검색결과가 노출되는 기준을 공개하도록 하였다.
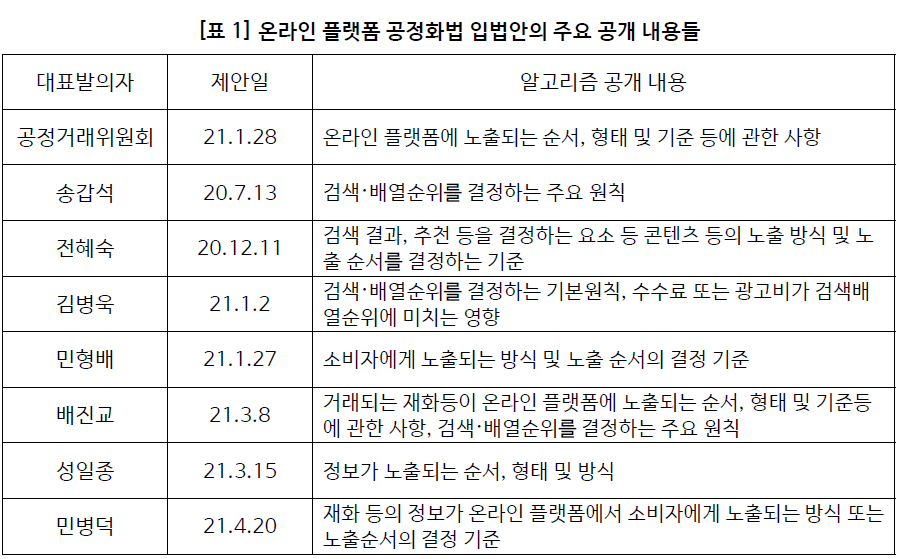
[표 2]는 최근 발의된 인터넷 뉴스에 관련된 신문법 개정안이다. 기본적으로 모든 안들이 기사배열 기준을 공개하도록 하고 있으며 또한 다수안이 배열책임자를 공개하도록 한다. 김남국, 이수진안은 이용자 위원회 혹은 자문 위원회를 구성하도록 강제하고 있으며 공개 요구 및 개선사항 권고 등을 담고 있다.
알고리즘 공개의 목적
알고리즘 공개를 법률로 강제하는 것은 검색편향을 막기 위해서이다. 검색편향이란 사업자가 의도적으로 순위를 조작하는 행위를 지칭한다. 구글은 2008년 “구글 쇼핑” 서비스를 시작하면서 자사 비교 쇼핑 서비스를 상단에 배치하였고 그 결과 자사 트래픽은 증가하고 경쟁사 트래픽은 대폭 감소하였다. 자사 트래픽이 영국은 45배, 독일은 35배 증가하였고 타사 트래픽은 영국이 85%, 독일이 92% 감소하였다. 유럽 연합 규제당국은 이 행위에 대해 2017년 3조원의 과징금을 부과하였다 (김연지 2017). 검색편향은 상품판매뿐만 아니라 선거에도 이용될 수 있다. 엡스타인과 로버트슨 박사는 2014년 인도 국회의원 선거에서 소위 검색엔진조작효과 (Search Engine Manipulation Effect)를 실험하였다. 특정후보에게 유리하게 검색결과를 보이도록 조작한 후 그것을 약 2000여명의 부동층 투표자에게 노출시켰다. 실험결과는 놀랍게도 이 편향된 검색 결과가 부동층 투표의 선호를 20%이상 변화시킬 수 있음을 보였다 (Epstein and Robertson 2015). 알고리즘에 의한 순위가 바뀜에 따라서 상품의 매출, 선거의 당락이 달라지기 때문에 이러한 알고리즘의 공정성은 정치/경제를 막론하고 무엇보다도 중요한 목적이 되었고 이의 공정성을 담보하는 것은 필요한 일이 되었다. 하지만 이러한 공정성을 어떻게 담보할 것인지에 대한 방법은 사회적 합의가 필요하다.
알고리즘 공개의 딜레마
검색 편향을 막고 알고리즘의 공정성을 담보하는 것이 중요하지만 알고리즘 공개는 몇 가지 문제를 야기한다. 첫째. 알고리즘을 소유하고 있는 기업의 입장에서 알고리즘은 경쟁력의 원천이다. 구글의 페이지랭크 (PageRank) 검색 알고리즘은 뛰어난 검색 능력으로 구글이 검색 엔진 사업에서 세계적인 독점기업으로 성장하는데 일조하였다. 또 좋은 알고리즘을 개발하는 것은 많은 노력이 필요한 지적재산이라는 점에서 이것의 공개는 기업 입장에서는 경쟁력 상실을 유발할 가능성이 있다.
둘째, 알고리즘은 계속적으로 진화하는 생물이다. 구글의 검색엔진은 페이지랭크에서 시작했지만 자연어를 처리할 수 있는 허밍버드 알고리즘을 추가하였고 계속적인 개선의 결과물이다 (Hachman 2013). 네이버나 다른 포탈의 검색 알고리즘도 마찬가지다. 그러나 알고리즘이 공개된다면 알고리즘을 개선하려는 동기가 사라질 수 있다는 문제점이 있다. 특허의 경우 공개하되, 개발자에게 독점사용권을 주면서 동기부여를 해주지만, 무조건적인 공개는 알고리즘 고도화 기회 상실로 연결될 수 있다.
셋째, 알고리즘의 공개는 지능적인 사용자에게 좀 더 세련된 어뷰징 기회를 제공한다. 검색엔진의 알고리즘을 이용하여 그 알고리즘 하에서 우선순위를 높일 수 있는 방법을 찾게 될 것이다. 예를 들어 구글의 페이지랭크 알고리즘을 아는 경우 가짜 링크들의 숫자를 늘림으로써 구글 검색엔진의 앞쪽에 노출될 가능성이 높아지게 할 수 있다. 이러한 어뷰징을 가치 중립적인 용어를 사용하면 검색엔진 최적화 (SEO: Search Engine Optimization)이라고 한다. 많은 온라인 마케팅 전문가들은 SEO를 이용하여 특정 상품과 상점의 노출을 높이고 있고 글로벌 SEO시장의 규모는 2021년 약 409억 불에 이른다 (SEO 2021).
알고리즘 공개의 정도
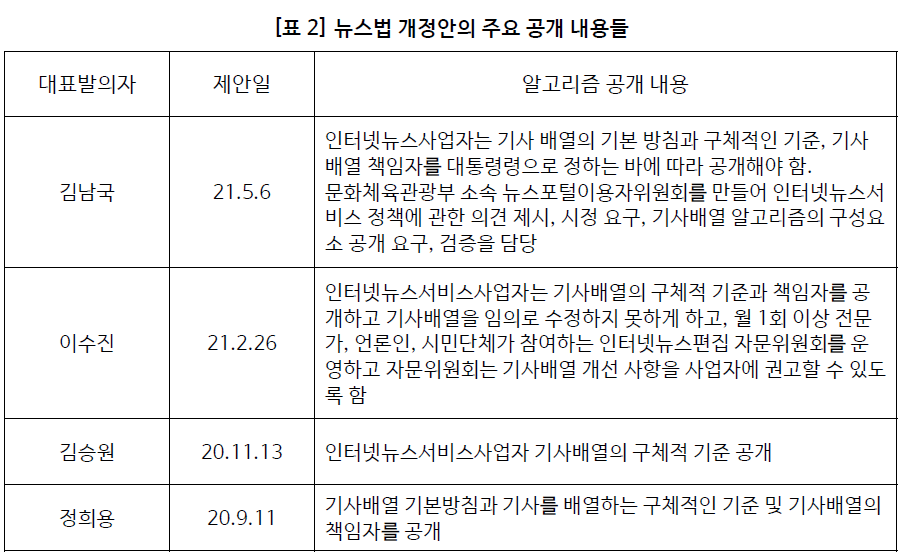
알고리즘의 공개는 그 정도에 따라 완전공개, 부분공개, 비공개로 구분할 수 있다. 완전공개는 오픈소스 프로젝트처럼 소스코드 전체를 공개하는 것을 이야기하고 비공개는 블랙박스처럼 소스코드를 오픈하지 않는 것이다. 그 사이에 부분공개는 다양한 스펙트럼이 존재할 수 있다. 현재 법안으로 제시되는 원칙이나 기준의 공개는 부분공개에 해당한다고 볼 수 있다.
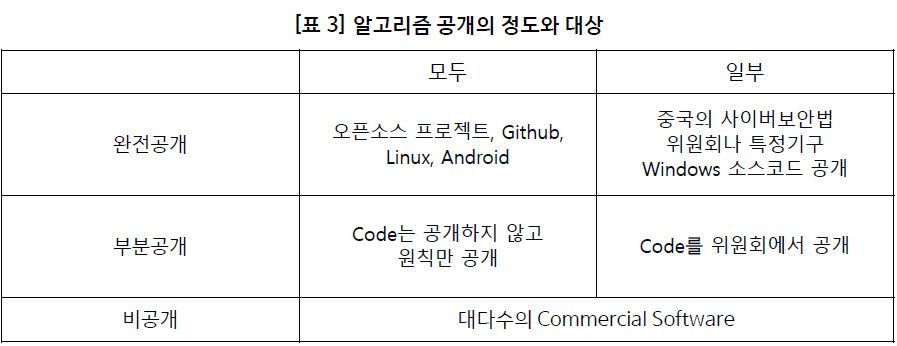
완전공개의 대표적 사례는 오픈소스 프로젝트 (Open Source Project)이다. 이것은 자발적으로 프로그램의 소스코드를 공개하여 누구나 사용할 수 있도록 해주는 것으로 리눅스 (Linux)가 대표적이다. 1991년 리누스 토발즈에 의해 공개된 리눅스는 유닉스 계열의 운영체제로 무료로 소스코드를 사용할 수 있고 또 누구든지 비상업적으로 이용, 수정, 배포가 가능하다. 이러한 리눅스는 훗날 혁신의 단초가 되어 다양한 플랫폼으로 이식되어 사용되고 있다. 안드로이드 운영체제를 비롯한 크롬북의 크롬OS, TV, 자동차의 OS도 리눅스를 기반으로 개발되었다. 또한, 최근 많은 인공지능 알고리즘이 오픈소스로 공개된다. Github이라는 저장소 사이트는 가장 많은 인공지능 알고리즘의 오픈 소스들이 공개되는 장소이다. 구글은 2015년에는 자체개발한 인공지능 플랫폼인 텐서플로우도 오픈소스로 공개하였다.
오픈소스 프로젝트가 자발적인 반면, 비자발적으로 소스코드 제출을 강제하는 상황은 중국에서 볼 수 있다. 중국 정부는 2016년 사이버보안을 명분으로 중국에 진출하는 해외 기업들에게 중국에서 사업을 하기 위해서는 소스코드 제출을 의무화하는 법안을 통과시켰다 (임민철 2016). IT대기업인 마이크로소프트, 인텔, IBM, 애플 등도 중국에서 사업을 하기 위해선 이 법의 적용을 피해갈 수 없었다. 법안에 따르면 소스코드의 공개는 모든 사람을 대상으로 공개하는 것은 아니고, 특정 국가기관이나 자문위원회에 한정되어 공개된다. 2016년 마이크로소프트는 중국에 소스코드를 공개할 때 마이크로소프트 투명성 센터 (Microsoft Transparency Center)를 베이징에 세웠다. 투명성센터는 정부가 소스코드를 리뷰할 수 있는 장소로 소스코드의 유출을 막고 센터안에서 정부의 전문가가 소스코드를 리뷰할 수 있도록 만든 센터이다. 이 경우 소스코드 공개대상은 정부의 특정인에 해당한다.
대다수의 상업용 소프트웨어는 그 소스코드가 공개되지 않는다. 소스코드가 지적재산권으로 보호되고 있고 기업의 경쟁력의 원천으로 생각하기 때문에 이를 공개하지 않는 것이 일반적이다. 최근 입법화되고 있는 알고리즘 공개는 검색결과의 기준과 원칙을 공개하라는 의미에서 완전공개는 아니고 부분공개에 해당한다고 볼 수 있다. "원칙과 기준"에 대한 공개는 법률을 통하여 모든 사람에게 공개되기 때문에 "모두 공개"에 해당한다. 하지만 "결과"부분에 대한 해명이 필요한 경우 당사자나 위원회에 설명을 하기 때문에 "부분공개"에 해당한다.
알고리즘 공개 정도가 미치는 영향
[표 4]는 4가지 알고리즘 공개 시나리오와 각 시나리오별 영향을 요약한 표이다. 4가지 시나리오는 1) 모두에게 완전공개, 2) 일부에게 완전공개, 3) 모두에게 부분공개, 4) 비공개이다.
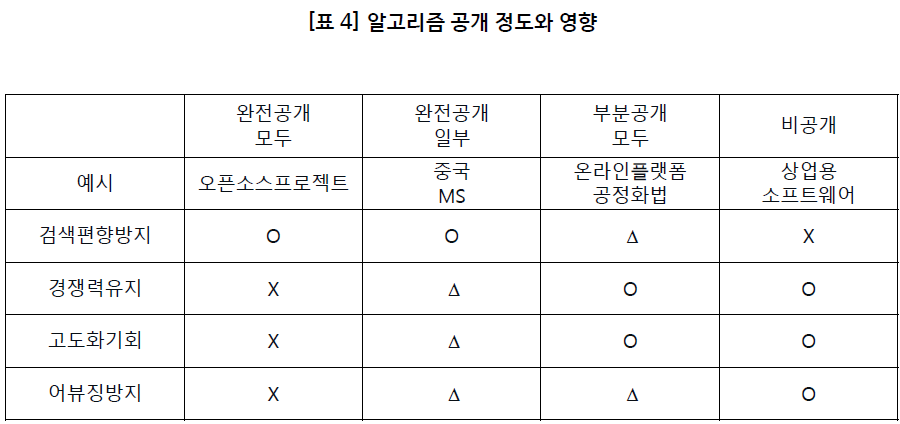
‘모두에게 완전공개’의 경우는 말 그대로 오픈소스 프로젝트처럼 소스코드를 완전히 공개하는 것이다. 이 경우는 검색편향방지는 효과적이겠지만 경쟁력 유지, 고도화 기회, 어뷰징 방지라는 3가지 목표를 달성하기 어려워지는 딜레마에 노출될 것이다. 그 반대의 경우가 네 번째의 ‘비공개’ 시나리오인데 이 경우 검색편향방지라는 목적이 달성되지 않는 현재의 상황에 해당한다. 두 번째 시나리오인 ‘일부에게 완전공개’의 경우엔 검색편향방지는 달성할 수 있고, 공개된 일부 그룹이 정보를 누설하지 않는 한 3가지의 딜레마에 노출되지 않는다는 장점이 있다. 즉, 우선적인 목적을 달성할 수 있고 딜레마에 대한 우려의 정도도 낮다는 점에서 효과적이다. 물론 이와 같은 결과는 공개된 일부가 신뢰할 수 있는 경우에 한해서만 달성될 수 있다. 예를 들어 알고리즘을 심사하는 위원회에 속해 있는 인사 중 한 명이 정보를 누출했을 경우, 기업의 경쟁력 유지와 고도화 기회 등은 달성하기 어려워질 수 있다.
현재 제안된 많은 법안들이 채택하고 있는 방법이 세 번째 시나리오인 ‘모두에게 부분공개’에 해당한다고 볼 수 있다. 알고리즘의 소스코드를 공개하는 것은 아니지만 큰 원칙을 공개하는 방법이다. 이 방법은 검색편향을 방지할 수 있을 것인가에 대한 효과성에 대한 의문이 있다. 원칙은 공개되었지만 만약 “악마는 디테일에 있다”는 말처럼 검색편향을 큰 원칙을 지키면서 예외적인 경우에 해당하는 다양한 방법으로 적용하게 되면 검색편향을 방지하지 못하게 될 가능성이 있다. 하지만 디테일이 공개되지 않음으로써 경쟁력 유지 측면이나 고도화 기회 측면에서는 유리한 방법이라고 볼 수 있다. 단 어뷰징의 위험성은 어느정도 정보가 확산됨에 따라 늘어날 가능성이 있다.
Big Data/인공지능시대의 알고리즘 공개
많은 인공지능 알고리즘은 데이터를 이용하여 학습을 하고 그 학습의 결과가 알고리즘이 된다. 예를 들면, Netflix나 쇼핑몰에서 사용되는 상품 추천 알고리즘은 사용자가 어떤 영화나 상품을 보았는가(데이터)에 따라서 추천 결과가 달라진다. 즉, 알고리즘의 결과가 주어진 데이터에 따라서 달라진다. 유튜브를 방문할 때 첫 화면에 보여지는 결과가 개인마다 차별화되는 것이 바로 그 예이다. 이 경우엔 검색편향성을 측정하는 것이 더 어려워진다.
뉴스를 볼 때, 보수 편향을 가진 사람에게는 보수적인 뉴스를 많이 추천해 주고, 진보 편향을 가진 사람에게는 진보 뉴스를 많이 추천한다 (프레이저 (2011)는 이러한 현상을 “필터버블”이라고 표현하였다). 이 경우 이러한 편향적인 뉴스 추천이 알고리즘의 편향성 때문인지, 아니면 사람을 표현하는 데이터의 편향성 때문에 나타나는 자연적인 결과인지를 판단하기가 어렵게 되는 것이다. 전자의 경우엔 알고리즘의 편향성을 골라내야 하지만 후자의 경우엔 편향적인 알고리즘이라고 하기 어려울 수 있다.
이처럼 알고리즘이 데이터와 분리되기 어렵기 때문에, 알고리즘만 공개해서 그것의 편향성을 파악하기가 불가능하다. 따라서 데이터를 같이 공개해야만 편향성을 판단할 수 있게 되는 것이다. 하지만 데이터의 공개는 데이터 사이즈의 문제도 있지만 개인정보 보호 (privacy) 이슈도 있기 때문에 공개하는 것이 쉽지만은 않다. Big data/AI시대의 알고리즘 편향성을 어떻게 판단할 것인가는 향후 연구되어야 할 주제이다.
살아있는 생물, 알고리즘의 공개
알고리즘은 계속적으로 변화하는 생물이다. 새로운 아이디어가 나오면 바뀌게 되고 또 환경이 바뀌면 새로운 제약조건이 추가되면서 바뀐다. 모든 소프트웨어는 바뀌는 알고리즘(소스코드)을 version이라는 숫자로 관리한다. 우리가 사용하는 “Windows 10”이라는 운영체제도 계속되는 패치를 이용하여 끊임없이 변화하는 것이다. 이러한 생물을 공개해서 관리하는 것은 규제 당국에게 새로운 행정적 업무이다. 주소록을 업데이트하는 것을 생각하면 된다. 주소록을 업데이트하려면 지속적으로 연락하면서 새로운 주소가 나올 때 마다 갱신해야 하는 것이다. 알고리즘의 공개도 마찬가지다. 최신 상태를 유지하기 위해선 많은 행정력이 동원되어야 한다.
알고리즘이 바뀔 때마다 편향성을 측정하는 방법이 바뀐다면 해당 규제당국도 편향성 측정방법을 계속적으로 개발해야 한다. 이러한 이유로 알고리즘 변화와 독립적일 수 있는 혹은 영향이 적은 편향성 측정방법이 필요하다. 이러한 방법은 아마도 블랙박스 어프로치가 적당할 것이다. 알고리즘의 세부내용과 무관한 편향성 측정 방법이 필요할 것이다.
마치며
현재 논의가 진행되고 있는 알고리즘 공개 방법은 원칙과 기준을 공개하는 방법이지만 이것만으로는 검색편향 방지를 효과적으로 달성할 수 있을지 의문스러운 측면이 있다. 또 인공지능 알고리즘의 편향성은 데이터에 기반하기 때문에 데이터를 동시에 공개하지 않으면 이 편향성을 찾기가 불가능할 수 있다. 또 한 가지 고려해야 할 점은 편향성 측정에 필요한 행정력도 고려해야 한다는 것이다. 계속적으로 변경될 것으로 예측되는 알고리즘마다 새로운 편향성 측정방법이 필요하다면 이것도 큰 일이 될 것으로 생각된다. 따라서 이러한 이슈들을 고려해서 추후 논의를 이어갈 필요가 있을 것으로 생각된다.
<참고문헌>
김연지. 2017. “EU, 구글에 3조 과징금…5가지 관전 포인트는”. 2017년 6월 28일, 조선일보, https://www.chosun.com/site/data/html_dir/2017/06/28/2017062801732.html
임민철. 2016. “中 "소스코드 줘"…MS·애플·인텔 "못줘”. 2016년 12월 26일, ZDNET 코리아, https://zdnet.co.kr/view/?no=20161206095831
Epstein, Robert, and Ronald E. Robertson. 2015. The search engine manipulation effect (SEME) and its possible impact on the outcomes of elections. Proceedings of the National Academy of Sciences, 112 (33): E4512-21.
Hachman, Mark. 2013. “구글의 새로운 검색 알고리즘 ‘허밍버드’ 공개… “결과가 아닌 답 제공 목표”. PC World, https://www.itworld.co.kr/news/83922
Pariser, Eli. 2011. 생각 조종자들 (당신의 의사결정을 설계하는 위험한 집단) (이정태, 이현숙 옮김). 서울: 알키.
SEO. 2021. Global Agencies SEO Services Market Report 2021.
https://www.businesswire.com/news/home/20210715005758/en/Global-Agencies-SEO-Services-Market-Report-2021
*디지털사회(Digital Society)는 연세대학교 디지털사회과학센터(Center for Digital Social Science)에서 발행하는 이슈브리프입니다. 디지털사회의 내용은 저자 개인의 견해이며, 디지털사회과학센터의 공식입장이 아님을 밝힙니다.
[디지털사회] 제36호
발행인: 조화순
발행일: 2021년 10월 20일
ISSN 2586-3525(Online)
전체 0
댓글을 남기려면 로그인하세요.