
디지털사회 제47호: AI 기반 방법론과 빅데이터의 사회적 활용
작성자
ssk
작성일
2023-05-02 00:59
조회
2713
AI 기반 방법론과 빅데이터의 사회과학적 활용
우병득(POSTECH 사회문화데이터사이언스연구소 연구교수)
들어가며사회과학적 연구질문을 탐색함에 있어 AI(Artificial Intelligence)와 빅데이터의 중요성이 지속적으로 조망되고 있다. 자동화된 분석기법으로서의 AI는 최근 폭발적으로 증가하고 있는 데이터의 양과 복잡성을 효율적으로 분석하기 위해 선택이 아닌 필수가 되고 있다. 특히, 자연어 처리 분야를 양분하고 있는 BERT(Bidirectional Encoder Representations from Transformers)와 GPT(Generative Pretrained Transformer)의 등장은 학자들에 더해서 일반 대중들 또한 AI가 일으킬 거대한 파도를 예측케 하고 있다. 또한 자연어 처리 뿐만 아니라, 비디오와 오디오 등 다양한 비정형 데이터를 분석함에 있어서도 AI 기법이 적극적으로 활용되고 있다(Marechal et al. 2019).
그렇다면, 현재 AI와 빅데이터는 사회과학 분야에서 어떠한 위치를 차지하고 있으며, 사회과학적 연구질문을 탐색하기 위해 이들은 어떠한 방식으로 활용되고 있을까? 본 글은 최근 사회과학적 연구질문들을 탐색하기 위해 부상하고 있는 AI와 빅데이터를 개괄적으로 살펴보고 융복합연구의 필요성을 조망한다. 이에 더해서, AI와 빅데이터에 기반한 융복합연구와 관련된 주의점 및 유의점을 살펴보는 것을 그 목적으로 한다.
AI와 AI 기반 방법론을 차용한 연구의 동향
AI란 기본적으로 사람과 같이 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템 혹은 분석방법을 의미한다. AI 기반 방법론을 차용한 연구의 동향을 살펴보기에 앞서서 AI의 하위 분야를 간단히 살펴보겠다. AI의 하위 분야 중 사회과학분야에서 가장 많이 활용되고 있는 것은 단연 머신러닝(Machine Learning)과 딥러닝(Deep Learning)이다. 머신러닝이란 알고리즘을 통해 데이터를 분석하고 분석 결과와 패턴을 컴퓨터가 스스로 인식하여 특정 프로그래밍이 부재한 상황 하에서도 컴퓨터가 지속적으로 학습과 분석을 반복하는 것을 총칭한다. 딥러닝이란 머신러닝에 활용되는 알고리즘 중 인공 신경망(Artificial Neural Network)을 기반으로 한 분석방법을 포괄적으로 지칭한다.
Lundberg와 Grahn(2022)의 연구에 따르면 최근 머신러닝과 딥러닝을 포함한 AI 기반의 방법론을 활용한 논문의 수는 크게 증가하고 있다. 전체 수를 기준으로 보았을 때 2012년 117개 논문에서 AI 기반 방법론이 활용된 것을 시작으로 2017년에는 4,920개의 논문이 AI 기반 방법론을 사용하였으며, 2021년에는 10,270여개의 논문에서 AI 기반 방법론을 활용했다. Lundberg와 Grahn(2022)이 모든 전공분야의 논문을 검토한 것이 아니라는 점을 고려하였을 때, 실재로 AI 기반 방법론을 활용한 연구의 수는 더욱 많을 것으로 예상할 수 있다.
AI 기반 방법론을 딥러닝, 클라우드 컴퓨팅(Cloud Computing), 그리고 고성능 컴퓨팅(High-Performance Computing) 등으로 구분하였을 경우, 2019년까지는 외부 서버를 활용해 분석 작업을 가능케하는 클라우드 컴퓨팅이 AI 기반 방법론에서 가장 많이 활용되었으나 2020년부터는 딥러닝을 활용한 AI 방법론이 적극적으로 활용되기 시작했다. 고성능 컴퓨팅은 큰 반등없이 지속적으로 활용되고 있는 모습을 보인다. 그렇다면 왜 딥러닝을 활용한 AI 방법론이 연구자들에 의해 적극적으로 활용되기 시작하였을까?
<그림 1> AI 기반 방법론 연구 추세
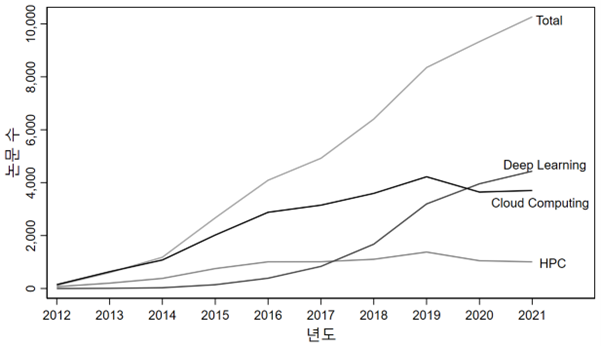
출처: Lundberg and Grahn (2022)의 데이터 재구성.
딥러닝을 활용한 방법론이 최근 들어 폭발적으로 증가하기 시작한 배경에는 텍스트, 비디오 혹은 이미지, 그리고 오디오 자료와 같은 비정형 데이터들을 통해 사회∙정치현상을 이해하고 분석하고자 하는 시도들이 태동하고 있다는 점이 있다. Bae et al. (2023)은 민원 빅데이터를 딥러닝 기반의 언어모형으로 분석하여 민원에 잠재된 민원인의 감정이 민원처리속도에 미치는 영향력을 검증하였으며, 이외에도 딥러닝 기반의 이미지 분석방법, 설문조사 시의 오디오 분석 방법들이 사회과학분야에 적용되고 있다(Joo and Steinert-Threlkeld 2018; Dietrich et al. 2019).
AI 기반 방법론과 빅데이터
빅데이터는 학자들에 따라 상이하게 정의되며 그 속성과 특징 역시 다양하게 서술된다. Acharjya and Ahmed (2016)에 따르면 빅데이터의 특징은 4V로 정의된다. 첫째, 빅데이터는 대규모(Volume)의 데이터를 의미한다. “대규모”의 범위 역시 연구자의 주관에 따라 다르지만 일반적으로 테라바이트(Terabytes) 혹은 페타바이트(Petabytes) 이상의 데이터를 의미한다. 둘째, 빅데이터는 데이터의 생성과 축적의 속도가 매우 빠른(Velocity) 데이터를 의미한다. 셋째, 빅데이터는 통계데이터 등의 정형적 데이터(Structured Data)와 텍스트, 비디오 등의 비정형적 데이터(Unstructured Data)를 모두 포함하는 다양성(Variety)을 특징으로 한다. 이를테면, SNS상의 유저들의 코멘트, 뉴스 기사, 유튜브에 게시되는 영상자료들 모두 빅데이터의 특징을 가지고 있다는 것이다. 넷째, 빅데이터는 진실성(Veracity)을 가지고 있어야 한다. 구체적으로 빅데이터는 데이터의 신뢰성과 타당성을 갖추고 있어야 한다는 점이다. 다시 말해, 빅데이터란 분석할 만한 가치가 있는 믿을 수 있는 데이터라는 의미다.
<그림 2> 빅데이터의 4V 특징
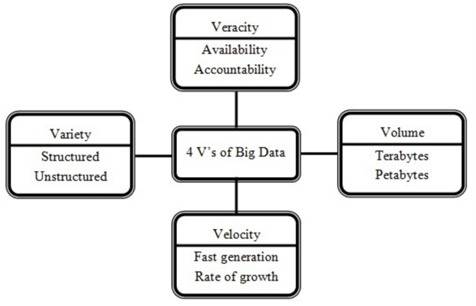
출처: Acharjya and Ahmed (2016)
이와 같은 특징들을 가지고 있는 빅데이터를 활용한 연구를 진행하기 위해서는 AI 기반의 접근방식이 필수에 가깝다. 데이터를 활용하는 연구는 기본적으로 1) 데이터의 수집, 2) 데이터의 정제, 저장, 모델링, 3) 데이터의 분석과 이에 대한 의미도출의 과정을 수행한다. 빅데이터의 경우 데이터의 수집 단계에서는 자동화된 데이터 수집 기법인 웹스크래핑(Web Scraping)이 주로 활용되며, 데이터의 정제와 저장 그리고 모델링의 단계에서는 R과 파이썬(Python) 등의 프로그램이 사용된다. AI가 가장 적극적으로 활용되는 단계는 데이터 분석 단계로, 특히 비정형 데이터를 분석함에 있어서 주로 활용된다. 자연어 처리에서는 BERT를 필두로 GPT와 같은 거대 언어모형이 발전하고 있으며, 이미지 데이터 분석의 CNN(Convolutional Neural Network), 오디오 분석의 Multimodal Embedding Algorithm 등이 주목받고 있다.
어떠한 학자들은 빅데이터의 특징으로 앞서 언급한 4개의 “V”들 이외에도 “가치(Value)”가 있는 데이터를 빅데이터의 특징으로 이야기한다(Zhang et al. 2017). 그러나, 대부분의 빅데이터는 그 자체만으로 가치를 가지지 못한다. 빅데이터에서 의미를 찾고 그 가치를 발견해내는 작업은 연구자들의 통찰과 역량에 의해 좌우된다. 연구자의 사회과학적 지식은 빅데이터에 의미를 부여하고 가치 있게 하며 이를 통해 사회과학적 연구질문을 보다 면밀하게 탐색할 수 있도록 하는데 주요한 역할을 한다.
AI, 빅데이터, 그리고 사회과학적 시각의 융복합연구
AI와 빅데이터는 최근 사회과학 연구에서 각광받고 있는 융복합 연구에서 주요한 역할을 차지하고 있다. 특히 사회과학 분야에서는 전통적 통계분석 방법을 포함한 양적방법론(Quantitative Methods), 빅데이터 분석으로 대표되는 컴퓨터과학(Computer Science), 그리고 사회과학에 대한 지식(Substantive Knowledge on Social Science)을 결합한 전산 사회과학(Computational Social Science)의 필요성이 강조되고 있다.
이러한 관심에도 불구하고 전산 사회과학은 아직 다음과 같은 취약점을 지니고 있다. 가장 먼저, 재현성 위기(Replication Crisis)가 나타날 수 있다. 재현성 위기란 학계 전반적으로 활발하게 논의되고 있는 문제로 출판된 논문들의 연구를 다른 학자들이 재현해 낼 수 없을 때 나타난다(Freese & Peterson 2017). 이는 지식의 과학적 축적이라는 학문의 주된 목적을 저해하는 매우 시급한 문제다. 사회과학분야에서는 양적접근법을 활용하고 있는 연구들의 결과를 재현해 낼 수 있도록 데이터와 분석 코드를 공유하는 식으로 재현성 위기를 극복해 나가는 움직임이 일어나고 있다. 그러나 빅데이터를 분석함에 활용되는 AI 기반의 분석방법은 필연적으로 고성능의 컴퓨터 혹은 서버(Server)가 필요한 경우가 대부분이다. 또한 대용량의 데이터를 공유하는 것이 어려울뿐더러 분석 코드가 있다하더라도 이를 재현함에는 굉장히 오랜 시간이 필요하며, 일반 연구자들의 경우에는 분석 코드를 활용한 재현이 불가능에 가까운 경우도 많다.
재현성 위기를 극복하기 위해서는 빅데이터에 대한 수집과정과 정제과정에 대한 자세한 서술과 설명, 데이터의 공유, 그리고 AI 기반의 분석방법에 대한 정확한 분석 코드와 절차를 기록한 코드북(Codebook)의 작성이 필수적이다. 또한 빅데이터에 대한 연구자의 자의적 해석의 위험성을 피하기 위해서는 통계적 방법론에 기초한 연구계획과 분석이 요구된다. 이러한 두가지 잠재적 문제에 더해서 개인정보의 중요성에 대한 자각과 조심성 또한 빅데이터에 대한 AI 분석을 진행하는 연구자들이 항상 인지하고 있어야 하는 문제다. 그럼에도 불구하고 여전히 빅데이터와 AI 기반의 분석방법에 대한 연구윤리와 데이터 공유에 대한 명확한 기준이 마련되어 있지 않은 실정이기에(Lazer et al. 2020), 제도적인 보완과 함께 연구자 스스로 이러한 문제에 대한 경각심을 가져야 할 것이다.
나가며
본 글에서는 AI와 빅데이터 그리고 융복합연구에 대해 살펴보았다. 빅데이터와 AI는 어느새 학계뿐만 아니라 일반 대중들과 기업들에게도 버즈워드(Buzzword)가 되었다. 빅데이터와 AI가 가지고 있는 가치와 중요성을 고려한다면 어쩌면 당연한 일일 것이다.
새로운 학풍의 등장이라고 할 수 있을 만큼, 그리고 전산 사회과학이라는 새로운 전공분야가 생겨날 만큼 AI 기반의 분석기법이 학계에 미치는 파장은 대단하다. 그동안 쉽게 연구되지 못했던 비정형 데이터에 대한 분석 역시 AI와 함께 활발하게 진행되고 있다. 이러한 상황 속에서 지식의 과학적 축적(Accumulation of Scientific Knowledge)을 위해 연구자들은 재현성 위기와 자의적 해석의 위험지역에 대한 비판적인 시각을 견지해야 할 것이다.
<참고문헌>
Acharjya, Debi Prasanna, & Ahmed, Kauser. 2016. "A survey on big data analytics: challenges, open research issues and tools". International Journal of Advanced Computer Science and Applications 7, No.2, 511-518.
Bae, Young, Woo, Byung-Deuk, Jung, Sungwon, Lee, Eunchae, Lee, Jiin, Lee, Mingu, & Park, Haegyun. 2023. "The Relationship Between Government Response Speed and Sentiments of Public Complaints: Empirical Evidence From Big Data on Public Complaints in South Korea". Sage open 13, No.2, 21582440231168048.
Dietrich, Bryce J, Mondak, Jeffery J, & Williams, Tarah. (2019). Using the audio from telephone surveys for political science research. Annual Meeting of the Society for Political Methodology. Boston, MA,
Freese, Jeremy, & Peterson, David. 2017. "Replication in social science". Annual Review of Sociology 43, 147-165.
Goldstein, Neal D, LeVasseur, Michael T, & McClure, Leslie A. 2020. "On the convergence of epidemiology, biostatistics, and data science". Harv Data Sci Rev 2, 1-19.
Joo, Jungseock, & Steinert-Threlkeld, Zachary C. 2018. "Image as data: Automated visual content analysis for political science". arXiv preprint arXiv:1810.01544.
Lazer, David MJ, Pentland, Alex, Watts, Duncan J, Aral, Sinan, Athey, Susan, Contractor, Noshir, Freelon, Deen, Gonzalez-Bailon, Sandra, King, Gary, & Margetts, Helen. 2020. "Computational social science: Obstacles and opportunities". Science 369, No.6507, 1060-1062.
Lundberg, Lars, & Grahn, Håkan. 2022. "Research Trends, Enabling Technologies and Application Areas for Big Data". Algorithms 15, No.8, 280.
Marechal, Catherine, Mikolajewski, Dariusz, Tyburek, Krzysztof, Prokopowicz, Piotr, Bougueroua, Lamine, Ancourt, Corinne, & Wegrzyn-Wolska, Katarzyna. 2019. "Survey on AI-Based Multimodal Methods for Emotion Detection". High-performance modelling and simulation for big data applications 11400, 307-324.
Zhang, Yaoxue, Ren, Ju, Liu, Jiagang, Xu, Chugui, Guo, Hui, & Liu, Yaping. 2017. "A survey on emerging computing paradigms for big data". Chinese Journal of Electronics 26, No.1, 1-12.
디지털사회(Digital Society)는 연세대학교 디지털사회과학센터(Center for Digital Social Science)에서 발행하는 이슈브리프입니다. 디지털사회의 내용은 저자 개인의 견해이며, 디지털사회과학센터의 공식입장이 아님을 밝힙니다.
전체 0
댓글을 남기려면 로그인하세요.