
디지털사회 제42호: 편향적 인공지능: 알고리즘으로 재생산되는 편향의 원인과 유형, 그리고 개선방안을 중심으로
작성자
ssk
작성일
2022-12-08 07:15
조회
17058
편향적 인공지능: 알고리즘으로 재생산되는 편향의 원인과 유형, 그리고 개선방안을 중심으로
들어가며
프로야구 한국시리즈 7차전 9회말 점수는 2대 1로 뒤지는 가운데 2사 만루의 역전과 최소 동점을 위한 절호의 공격 기회를 맞이한 홈팀. 홈 관중은 승리를 염원하며 극도의 긴장감과 기대감에 숨죽이게 되고 상대 팀의 마무리 투수는 2스트라이크 3볼의 상황에서 힘차게 공을 던진다. 타자는 공이 스트라이크존을 한참 벗어났다는 판단과 함께 볼넷으로 동점을 만들었다는 환호로 두 팔을 들어 올리지만, 그와 동시에 울리는 심판의 스트라이크 콜! 그대로 경기는 종료되며 상대 팀의 우승이 확정된다. 하지만 스트라이크존을 벗어난 것처럼 보이는 마지막 공이 중계화면에 잡히고 이 영상이 느린 화면으로 반복 재생되며 홈 관중은 물론 집에서 중계를 지켜보던 시청자들 역시 분노에 휩싸인다. 동시에 프로야구 온라인 게시판과 소셜미디어는 심판에 대한 비난으로 도배가 되며 심판의 자질 부족을 질타하는 것은 물론 상대 팀과의 결탁까지 의심하는 글도 속속 올라온다. 그리고 심판에 대한 비난은 곧 인공지능 심판의 도입이 하루빨리 이뤄져야 한다는 청원 운동으로 이어져 이틀 만에 20만명이 서명하는 일이 발생한다.
물론 이것은 가상의 이야기다. 하지만 프로야구 팬은 물론 스포츠에 별 관심이 없는 사람들까지 심판의 오심으로 인한 비난과 조롱이 어제 오늘의 문제가 아니었다는 점에 공감할 것이다. 그리고 이러한 오심 문제가 불거질 때마다 해결책으로 제시되는 방안은 인공지능 심판의 도입이다. 즉, 심판은 인간이기 때문에 실수(무작위 오류)를 범할 수도 있을 뿐만 아니라 특정 팀에 편향(체계적 오류)된 판정을 내릴 수 있다는 것이다. 여기에는 인공지능 심판은 인간이기에 범할 수 있는 실수는 물론 주관성과 편향으로부터 자유롭게 때문에 객관적이고 공정한 판정을 내릴 것이라는 기대가 깔려있다. 하지만 과연 인공지능 심판은 공정한 판정으로 인간의 오류를 완벽히 해결하는 구원자가 될 것인가?
세상 대다수의 일이 그러하듯 이 질문에는 낙관과 비관의 전망이 공존한다. 낙관적 기대를 보내는 사람들은 인공지능이 중립적이고 불편부당한 심판자로서 합리적인 의사결정을 도출하는데 효과적이라 믿는다. 여기에는 인간의 선입견과 이기심 등이 원인이 돼 정보를 수집하고 처리해 의사결정을 내리는 과정에서 편향성이 작동할 수 있다는 전제가 깔려있다. 즉, 인간으로서 어쩌면 당연한 자신의 이익을 추구하고 믿음을 확인하려는 본능 혹은 심리를 감안한다면 이러한 인간적 한계로부터 자유로운 인공지능의 객관적이고 합리적인 판단이 의사결정의 많은 부분을 대체할 수 있다는 것이다.
반면, 비관적 시선은 인공지능의 편향성에 주목한다. 인공지능 역시 인간의 의도와 성향은 물론 사회적 편향이 반영된 산물로 불공정한 결정을 내릴 수 있다는 것이다. 여기에서 편향이란 인간 사고나 판단의 습관으로 객관적이고 중립적이지 않아 한쪽으로 치우친 불공정한 평가를 의미하는 것으로 편향된 정보의 수용과 지각적 처리는 사회적 산물인 고정관념, 편견, 차별, 혐오 등을 만들어 낼 수 있다. 그렇다면 어떠한 원인과 이유로 인공지능이 편향성으로부터 자유롭지 않다는 것일까? 이 글에서는 위 질문에 대한 해답을 고민하고자 인공지능 편향성의 원인과 유형, 그리고 문제를 개선할 수 있는 기술 및 정책적 방안을 논의하고자 한다.
인공지능과 편향성
우선, 인공지능이란 무엇인가? 인공지능은 대규모 데이터 세트와 이를 처리하는 컴퓨팅 능력 발달로 이전에는 가능하지 않았던 고차원의 방정식 문제를 빠르고 정확하게 해결하기 위한 예측 또는 결정을 내리는 기계 기반 시스템을 의미한다. 특히 매우 다양한 요인이 복잡하게 작용하는 상황에서 과거의 결정을 재현 혹은 개선하기 위해 빅데이터를 “신경망(neural networks)“이라 불리는 기계학습(machine learning)의 모델링 기술로 처리해 정확한 예측을 내릴 수 있게 됨에 따라 인공지능이 실생활에 적용되는 영역이 빠르게 늘어나고 있다. 비용 절감은 물론 더 정확하고 효과적인 예측이 가능한 인공지능은 투자 결정 및 거래 자동화, 질병 진단 및 치료법 제안, 최적의 교통 경로 선택, 작물 및 토양의 건강 모니터링 및 환경 영향 예측, 범죄 재발 위험도 평가 등 경제, 의료, 운송, 농업, 사법의 많은 영역에서 응용되고 있으며 그 범위가 계속 확장되는 추세다.
그렇다면 어떠한 이유에서 인공지능의 편향성 문제가 불거지는 것일까? 인공지능의 공정성에 대한 우려가 지속적으로 제기되는 데에는 공정하기보단 편향을 재생산하거나 강화하는 방식으로 작동하는 알고리즘에 대한 회의가 자리한다. 인공지능 시스템은 주어진 문제를 해결하는 일련의 절차인 알고리즘에 기반하는데 알고리즘은 과거 데이터를 학습해 최적의 결과를 산출할 뿐만 아니라 데이터가 추가될수록 이를 조정하는 방식을 취한다. 따라서 끊임없이 발달하는 알고리즘을 활용해 현실 세계의 복잡하고 다양한 문제들을 효율적으로 해결하는 영역이 점차 넓어지는 추세다. 문제는 이러한 알고리즘이 개발되고 활용되는 과정에서 지금껏 존재해 온 편향성이 발현되고 있다는 것이다. 결국, 인공지능은 개인 혹은 사회적 차원에서 작동하는 편향성이 반영된 산물로 다음의 세 가지 차원에서 이를 재생산한다.
개인의 편향성
첫 번째, 개인의 편향성이 인공지능으로 강화되는 경우다. 즉, 인공지능 알고리즘이 사용자의 취향과 선호를 반영하는 검색기록 등의 데이터를 학습하고 이에 따른 맞춤형 정보와 뉴스, 영상 등을 선택해 추천함으로써 개인이 기존에 갖고 있던 편향성을 강화하도록 작동한다는 것이다. 이렇게 알고리즘이 개인 맞춤형 서비스를 제공함으로써 결과적으로 사용자가 본인의 관심사와 기호 등에 일치하는 정보에만 노출되는 현상을 “필터버블(filter bubble)”이라고 한다. 이 현상은 인간이 자신의 신념과 일치하는 정보는 수월하게 받아들이고 그렇지 않은 정보는 무시하거나 거부하는 경향인 확증편향(confirmation bias)을 인공지능이 부추김으로써 사회적 분열과 갈등을 조장할 수 있다는 비판을 낳고 있다. 실제 소셜미디어를 통한 사회적 교류와 정보 습득은 정치적 편향이 강화되는 방식으로 나타나고 있는데 <그림 1>은 자동화 방식으로 구현된 봇(bot) 계정 중 정치적으로 중립적인 계정에 비해 보수 혹은 진보의 색채가 보다 강한 계정에 많은 수의 팔로워가 생기고 있음을 보여준다. 이 결과는 인간 사용자의 편향성이 통제되더라도 친구 추천과 같은 소셜미디어의 알고리즘이 사용자 간의 교류에서 발현되는 확증편향을 강화하는 방식, 즉 자신의 견해 혹은 신념과 일치하는 정보가 증폭되는 반향실 효과(echo chamber)를 촉진하는 방식으로 작동하고 있음을 제시한다.
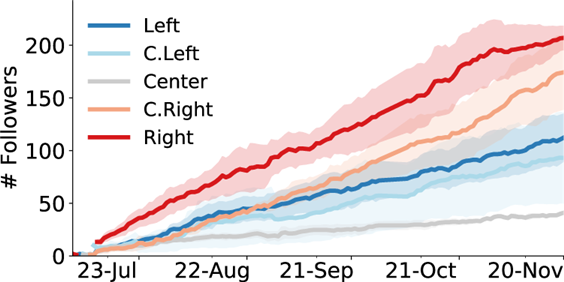
자료: Chen, W. et al. (2021)
권력의 편향성
두 번째, 권력의 편향성이 인공지능을 이용하는 경우다. 즉, 정권의 유지 및 지지여론 강화는 물론 반대 목소리를 잠재우기 위한 용도로 인공지능이 활용되고 있다는 것으로 이러한 사례는 민주주의가 발전한 국가에서도 발견되는 전 세계적인 현상으로 보고되고 있다(Howard, 2020). 가령, <그림 2>는 2020년 미국 대통령 선거에 관련해 약 2억 4천만건 이상의 트윗을 분석한 결과로서 인간이 아닌 알고리즘으로 운영되는 봇 계정이 진보와 보수를 막론하고 인간 계정에 비해 훨씬 많은 트윗을 게시하고 있음을 보여준다. 더욱이 이러한 봇 계정의 활동은 전당대회와 같은 주요 정치적 이벤트 기간에 더욱 활발해지며 음모론 관련 해시태그를 집중적으로 유포하는 것으로 나타났다. 이것은 컴퓨테이셔널 선전(computational propaganda)의 결과로 인공지능이 여론을 호도하기 위한 악의적 목적으로 활용되고 있음을 제시한다(Woolley & Howard, 2019). 더욱 심각한 문제는 이러한 정치적 용도의 알고리즘이 소수의 인원만으로 여론을 형성하거나 바꾸는 실질적 계책(maneuver)이 될 수 있다는 것으로 특히 소셜미디어 네트워크를 통해 오정보(misinformation)는 물론 허위조작정보(disinformation)를 유포하여 정치적으로 편향된 담론이 조성되는데 인공지능이 활용되고 있다는 것이다.
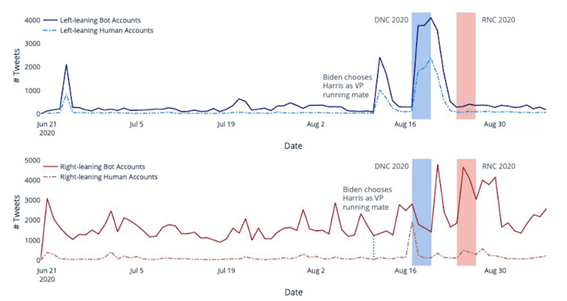
자료: Ferrara, E. et al. (2020)
사회적 편향성
세 번째, 사회적 편향성이 인공지능에 반영되어 나타나는 경우다. 알고리즘이 학습하는 데이터에 사회적으로 구조화된 편향성이 내재하고 있어 인공지능 역시 편향된 성능을 보이게 된다는 것이다. 다시 말해, 인공지능 알고리즘은 데이터에서 예측 변인을 설명하는 주요 특징을 도출해 이를 최적화 모델로 추상화해 정보 혹은 행동을 위한 추론을 하는 시스템이기 때문에 데이터가 표상하는 특징이 차별 혹은 불공정성을 유발할 수 있다. 가령, 이미지나 비디오에서 사람을 식별하기 위해 개발되고 있는 안면인식 시스템의 알고리즘은 이목구비의 위치와 모양의 특징을 구분하기 위한 학습으로 얼굴 데이터를 이용하는데 여기에 특정 인종과 성별, 연령의 얼굴이 과대 혹은 과소 포함되어 있다면 편향된 결과가 도출될 수 있다. <그림 3>은 안면인식 시스템이 미국의 오바마 전 대통령의 얼굴을 젊은 백인 남성의 얼굴로 인식한 결과를 통해 데이터의 불균형에 따른 인공지능의 편향성을 지적하고 있다. 즉, 시스템 사용자는 물론 권력을 가진 의사결정권자 누구의 편향적 의도가 개입하지 않아도 인공지능 알고리즘이 편향된 결과를 도출할 수 있다는 것이다. 이것은 빅데이터의 관점에서 개인의 무의식적 행동까지 최대한의 흔적이 수집되며 사회적 산물인 불평등과 차별, 편견이 내재한 데이터가 구성되고 이를 인공지능의 알고리즘이 학습해 개발자나 사용자의 의도와는 무관한 편향이 발생할 수 있음을 의미한다.

자료: @Chicken3gg [Tweet]. https://twitter.com/Chicken3gg
인공지능 편향성의 개선방안
위에서 논의한 인공지능의 편향성은 그 유형별 원인을 고려할 때 어떻게 개선될 수 있을까? 첫째, 개인의 편향성이 인공지능으로 강화되는 경우는 개인의 성향과 이에 대한 맞춤형 서비스로 수익을 창출하는 추천 알고리즘의 속성이 문제의 원인이다. 이에 미디어 리터러시 교육을 통해 콘텐츠 이용자에게 편향 가능성에 대한 비판적 인식을 촉진하고 알고리즘의 사회적 책임을 디지털 플랫폼 기업에게 요구함과 동시에 공영방송과 같은 공공 인터넷 플랫폼의 개발 등의 방안이 해결책이 될 수 있다. 둘째, 권력의 편향성이 인공지능으로 발현되는 경우는 정부 혹은 정당이 주축이 되어 정치적 목적의 선전을 펼치기 위한 알고리즘 활용이 문제의 원인이다. 따라서 저널리즘 차원에서 오히려 알고리즘을 적극 활용해 온라인에서 벌어지는 정치적 선전을 지속적으로 감시하고 인공지능 악용에 대항하는 노력이 필요하다. 또한 소셜미디어 플랫폼 기업들에게 악의적 봇 계정들에 대한 탐지와 제거를 요구하는 제도적 장치를 마련하는 것 역시 개선방안이 될 수 있다.
데이터의 편향성이 인공지능에 반영된 경우는 앞선 두 문제보다 신중한 접근을 요구한다. 왜냐하면 알고리즘 개발자나 사용자의 의도와는 무관하게 편향된 결과가 발생할 수 있기 때문으로 개선의 책임과 노력을 요구할 대상이 불분명한 것이 그 이유다. 사실 이러한 유형의 데이터의 편향은 알고리즘의 설계와 사용의 의도와는 상관없이 발생하는 일명 숨겨진 편향으로 일상의 세밀한 부분까지 포함하는 대단위 데이터를 구축해 인공지능의 예측 성능을 높일수록 현실 세계에 존재하는 사회적 편향이 반영된다는 역설이 존재한다. 즉, 객관적으로 구성된 데이터가 사회적 불균형을 반영하고 있어 이를 학습한 인공지능 역시 편향을 가지게 된다는 것이다. 미국의 강력 범죄자 데이터로 학습시킨 인공지능이 범죄 피의자에 대한 유죄 여부를 판단할 땐 기존 데이터 구성의 다수를 차지하는 흑인 남성에게 불리한 결과를 도출하는 것은 사법 영역에서 발현된 인종에 대한 사회적 편견과 불평등이 인공지능에 의해 재생산된 것이라는 주장(Angwin et al., 2016)은 위의 관점에서 볼 때 일견 타당하다.
숨겨진 편향을 드러내고 감시하기
그렇다면 데이터 문제로 인한 인공지능의 편향성은 어떻게 개선될 수 있을까? 데이터의 편향을 해소하는 방안은 중립적이고 공정하게 데이터의 구성이 전제되어야 하지만, 사실 이 조건을 달성하기 위한 연역적 접근은 간단한 문제가 아니다. 중립적이고 공정하게 구성된 데이터가 정확히 무엇이고 어떻게 수집 가능한 것인지에 대한 일치된 견해가 마련되기 어렵기 때문이다.
반면 데이터의 어떠한 특성이 알고리즘의 편향된 예측 결과에 영향을 미치는지 귀납적으로 검사하고 평가하는 방식이 현실적으로 효과적인 대안이 될 수 있다. 그리고 이를 위해서는 데이터 구성 및 알고리즘 개발에 있어 투명성(transparency)과 설명가능성(explainability)을 요구하는 제도적 장치가 마련되어야 함은 물론이다. 관련 전문가의 주도로 FAT/ML(fairness, accountability and transparency in machine learning) 조직이 출범해 책임성(responsibility), 설명가능성(explainability), 정확성(accuracy), 감사 가능성(auditability), 공정성(fairness)의 5가지 원칙으로 알고리즘 개발과 데이터 구성이 이뤄져야 함을 제시한 것 역시 같은 문제의식의 발로이다(Diakopoulos et al., 2017).
더욱이, 알고리즘 개발자 입장에서는 인공지능 성능의 정확성과 효율성이 중요한 가치이기 때문에 외부의 신뢰할 만한 기관에서 공정성에 대한 평가를 수행할 수 있는 공공기관을 통한 감시 및 기준 체계가 설치될 필요가 있다(정희태 외, 2019). 이러한 필요성에 대한 응답으로서 우리나라의 경우 과학기술정보통신부 주도로 인간중심의 신뢰할 수 있는 인공지능 실현 전략을 세우고 2026년까지 5년간 설명가능하고 공정하며 견고한 인공지능 개발과 검증 및 인증 체계의 마련을 추진한다는 계획을 발표한 바 있다.
더 나아가, 관련 학계 역시 데이터로 인한 알고리즘의 편향성에 대한 관심을 바탕으로 실증분석에 기초한 평가를 위해 지속적인 노력을 기울여야 한다. 가령, 네이버가 악플 탐지를 위해 개발한 인공지능 서비스인 ‘클린봇’의 편향 가능성을 진단하기 위해 악플로 분류된 댓글과 그렇지 않은 댓글을 실증적으로 비교하고 그 대상 집단에 따라 성능 차이가 발생하고 있음을 지적한 연구(이신행, 2021)는 데이터에 숨겨진 편향을 드러내고 이를 개선하기 위한 시도이다.
인공지능의 편향성 문제를 개선하는 방안은 지금까지 논의한 다층적인 노력들이 확립되고 어우러질 때 실현 가능하다. 그리고 그것이 우리가 기대하는 신뢰할 수 있는 공정한 인공지능에 한 발 더 가까워지는 길이 될 것이다.
<참고문헌>
이신행. (2021). 편향적 인공지능: 네이버의 악플 탐지용 인공지능 ‘클린봇’이 판별한 혐오표현의 유형 분석. <사이버커뮤니케이션학보>, 38권 4호, 33-75.
Angwin, J., Larson, J., Mattu, S. and Kirchner, L. (2016.05.23.), ʻMachine bias: There’s software used across the country to predict future criminals. And it’s biased against blacksʼ, ProPublica.
[https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing]
Chen, W., Pacheco, D., Yang, K.-C., & Menczer, F. (2021). Neutral bots probe political bias on social media. Nature Communications, 12(1), 5580. https://doi.org/10.1038/s41467-021-25738-6
Chicken3gg. [@Chicken3gg]. (June 20, 2020). [Tweet]. https://twitter.com/Chicken3gg
Diakopoulos, N. et al. (2017). Principles for accountable algorithms and a social impact statement for algorithms. URL:
https://www.fatml.org/resources/principles-for-accountable-algorithms
Ferrara, E., Chang, H., Chen, E., Muric, G., & Patel, J. (2020). Characterizing social media manipulation in the 2020 U.S. presidential election. First Monday, 25(11). https://doi.org/10.5210/fm.v25i11.11431
Howard, P. N. (2020). Lie machines: How to save democracy from troll armies, deceitful robots, junk news operations, and political operatives. Yale University Press. https://doi.org/10.2307/j.ctv10sm8wg
Woolley, S. C., & Howard, P. N. (2019). Computational propaganda: Political parties, politicians, and political manipulation on social media.
디지털사회(Digital Society)는 연세대학교 디지털사회과학센터(Center for Digital Social Science)에서 발행하는 이슈브리프입니다. 디지털사회의 내용은 저자 개인의 견해이며, 디지털사회과학센터의 공식입장이 아님을 밝힙니다.
이신행(중앙대학교 미디어커뮤니케이션학부 조교수)
들어가며
프로야구 한국시리즈 7차전 9회말 점수는 2대 1로 뒤지는 가운데 2사 만루의 역전과 최소 동점을 위한 절호의 공격 기회를 맞이한 홈팀. 홈 관중은 승리를 염원하며 극도의 긴장감과 기대감에 숨죽이게 되고 상대 팀의 마무리 투수는 2스트라이크 3볼의 상황에서 힘차게 공을 던진다. 타자는 공이 스트라이크존을 한참 벗어났다는 판단과 함께 볼넷으로 동점을 만들었다는 환호로 두 팔을 들어 올리지만, 그와 동시에 울리는 심판의 스트라이크 콜! 그대로 경기는 종료되며 상대 팀의 우승이 확정된다. 하지만 스트라이크존을 벗어난 것처럼 보이는 마지막 공이 중계화면에 잡히고 이 영상이 느린 화면으로 반복 재생되며 홈 관중은 물론 집에서 중계를 지켜보던 시청자들 역시 분노에 휩싸인다. 동시에 프로야구 온라인 게시판과 소셜미디어는 심판에 대한 비난으로 도배가 되며 심판의 자질 부족을 질타하는 것은 물론 상대 팀과의 결탁까지 의심하는 글도 속속 올라온다. 그리고 심판에 대한 비난은 곧 인공지능 심판의 도입이 하루빨리 이뤄져야 한다는 청원 운동으로 이어져 이틀 만에 20만명이 서명하는 일이 발생한다.
물론 이것은 가상의 이야기다. 하지만 프로야구 팬은 물론 스포츠에 별 관심이 없는 사람들까지 심판의 오심으로 인한 비난과 조롱이 어제 오늘의 문제가 아니었다는 점에 공감할 것이다. 그리고 이러한 오심 문제가 불거질 때마다 해결책으로 제시되는 방안은 인공지능 심판의 도입이다. 즉, 심판은 인간이기 때문에 실수(무작위 오류)를 범할 수도 있을 뿐만 아니라 특정 팀에 편향(체계적 오류)된 판정을 내릴 수 있다는 것이다. 여기에는 인공지능 심판은 인간이기에 범할 수 있는 실수는 물론 주관성과 편향으로부터 자유롭게 때문에 객관적이고 공정한 판정을 내릴 것이라는 기대가 깔려있다. 하지만 과연 인공지능 심판은 공정한 판정으로 인간의 오류를 완벽히 해결하는 구원자가 될 것인가?
세상 대다수의 일이 그러하듯 이 질문에는 낙관과 비관의 전망이 공존한다. 낙관적 기대를 보내는 사람들은 인공지능이 중립적이고 불편부당한 심판자로서 합리적인 의사결정을 도출하는데 효과적이라 믿는다. 여기에는 인간의 선입견과 이기심 등이 원인이 돼 정보를 수집하고 처리해 의사결정을 내리는 과정에서 편향성이 작동할 수 있다는 전제가 깔려있다. 즉, 인간으로서 어쩌면 당연한 자신의 이익을 추구하고 믿음을 확인하려는 본능 혹은 심리를 감안한다면 이러한 인간적 한계로부터 자유로운 인공지능의 객관적이고 합리적인 판단이 의사결정의 많은 부분을 대체할 수 있다는 것이다.
반면, 비관적 시선은 인공지능의 편향성에 주목한다. 인공지능 역시 인간의 의도와 성향은 물론 사회적 편향이 반영된 산물로 불공정한 결정을 내릴 수 있다는 것이다. 여기에서 편향이란 인간 사고나 판단의 습관으로 객관적이고 중립적이지 않아 한쪽으로 치우친 불공정한 평가를 의미하는 것으로 편향된 정보의 수용과 지각적 처리는 사회적 산물인 고정관념, 편견, 차별, 혐오 등을 만들어 낼 수 있다. 그렇다면 어떠한 원인과 이유로 인공지능이 편향성으로부터 자유롭지 않다는 것일까? 이 글에서는 위 질문에 대한 해답을 고민하고자 인공지능 편향성의 원인과 유형, 그리고 문제를 개선할 수 있는 기술 및 정책적 방안을 논의하고자 한다.
인공지능과 편향성
우선, 인공지능이란 무엇인가? 인공지능은 대규모 데이터 세트와 이를 처리하는 컴퓨팅 능력 발달로 이전에는 가능하지 않았던 고차원의 방정식 문제를 빠르고 정확하게 해결하기 위한 예측 또는 결정을 내리는 기계 기반 시스템을 의미한다. 특히 매우 다양한 요인이 복잡하게 작용하는 상황에서 과거의 결정을 재현 혹은 개선하기 위해 빅데이터를 “신경망(neural networks)“이라 불리는 기계학습(machine learning)의 모델링 기술로 처리해 정확한 예측을 내릴 수 있게 됨에 따라 인공지능이 실생활에 적용되는 영역이 빠르게 늘어나고 있다. 비용 절감은 물론 더 정확하고 효과적인 예측이 가능한 인공지능은 투자 결정 및 거래 자동화, 질병 진단 및 치료법 제안, 최적의 교통 경로 선택, 작물 및 토양의 건강 모니터링 및 환경 영향 예측, 범죄 재발 위험도 평가 등 경제, 의료, 운송, 농업, 사법의 많은 영역에서 응용되고 있으며 그 범위가 계속 확장되는 추세다.
그렇다면 어떠한 이유에서 인공지능의 편향성 문제가 불거지는 것일까? 인공지능의 공정성에 대한 우려가 지속적으로 제기되는 데에는 공정하기보단 편향을 재생산하거나 강화하는 방식으로 작동하는 알고리즘에 대한 회의가 자리한다. 인공지능 시스템은 주어진 문제를 해결하는 일련의 절차인 알고리즘에 기반하는데 알고리즘은 과거 데이터를 학습해 최적의 결과를 산출할 뿐만 아니라 데이터가 추가될수록 이를 조정하는 방식을 취한다. 따라서 끊임없이 발달하는 알고리즘을 활용해 현실 세계의 복잡하고 다양한 문제들을 효율적으로 해결하는 영역이 점차 넓어지는 추세다. 문제는 이러한 알고리즘이 개발되고 활용되는 과정에서 지금껏 존재해 온 편향성이 발현되고 있다는 것이다. 결국, 인공지능은 개인 혹은 사회적 차원에서 작동하는 편향성이 반영된 산물로 다음의 세 가지 차원에서 이를 재생산한다.
개인의 편향성
첫 번째, 개인의 편향성이 인공지능으로 강화되는 경우다. 즉, 인공지능 알고리즘이 사용자의 취향과 선호를 반영하는 검색기록 등의 데이터를 학습하고 이에 따른 맞춤형 정보와 뉴스, 영상 등을 선택해 추천함으로써 개인이 기존에 갖고 있던 편향성을 강화하도록 작동한다는 것이다. 이렇게 알고리즘이 개인 맞춤형 서비스를 제공함으로써 결과적으로 사용자가 본인의 관심사와 기호 등에 일치하는 정보에만 노출되는 현상을 “필터버블(filter bubble)”이라고 한다. 이 현상은 인간이 자신의 신념과 일치하는 정보는 수월하게 받아들이고 그렇지 않은 정보는 무시하거나 거부하는 경향인 확증편향(confirmation bias)을 인공지능이 부추김으로써 사회적 분열과 갈등을 조장할 수 있다는 비판을 낳고 있다. 실제 소셜미디어를 통한 사회적 교류와 정보 습득은 정치적 편향이 강화되는 방식으로 나타나고 있는데 <그림 1>은 자동화 방식으로 구현된 봇(bot) 계정 중 정치적으로 중립적인 계정에 비해 보수 혹은 진보의 색채가 보다 강한 계정에 많은 수의 팔로워가 생기고 있음을 보여준다. 이 결과는 인간 사용자의 편향성이 통제되더라도 친구 추천과 같은 소셜미디어의 알고리즘이 사용자 간의 교류에서 발현되는 확증편향을 강화하는 방식, 즉 자신의 견해 혹은 신념과 일치하는 정보가 증폭되는 반향실 효과(echo chamber)를 촉진하는 방식으로 작동하고 있음을 제시한다.
자료: Chen, W. et al. (2021)
권력의 편향성
두 번째, 권력의 편향성이 인공지능을 이용하는 경우다. 즉, 정권의 유지 및 지지여론 강화는 물론 반대 목소리를 잠재우기 위한 용도로 인공지능이 활용되고 있다는 것으로 이러한 사례는 민주주의가 발전한 국가에서도 발견되는 전 세계적인 현상으로 보고되고 있다(Howard, 2020). 가령, <그림 2>는 2020년 미국 대통령 선거에 관련해 약 2억 4천만건 이상의 트윗을 분석한 결과로서 인간이 아닌 알고리즘으로 운영되는 봇 계정이 진보와 보수를 막론하고 인간 계정에 비해 훨씬 많은 트윗을 게시하고 있음을 보여준다. 더욱이 이러한 봇 계정의 활동은 전당대회와 같은 주요 정치적 이벤트 기간에 더욱 활발해지며 음모론 관련 해시태그를 집중적으로 유포하는 것으로 나타났다. 이것은 컴퓨테이셔널 선전(computational propaganda)의 결과로 인공지능이 여론을 호도하기 위한 악의적 목적으로 활용되고 있음을 제시한다(Woolley & Howard, 2019). 더욱 심각한 문제는 이러한 정치적 용도의 알고리즘이 소수의 인원만으로 여론을 형성하거나 바꾸는 실질적 계책(maneuver)이 될 수 있다는 것으로 특히 소셜미디어 네트워크를 통해 오정보(misinformation)는 물론 허위조작정보(disinformation)를 유포하여 정치적으로 편향된 담론이 조성되는데 인공지능이 활용되고 있다는 것이다.
자료: Ferrara, E. et al. (2020)
사회적 편향성
세 번째, 사회적 편향성이 인공지능에 반영되어 나타나는 경우다. 알고리즘이 학습하는 데이터에 사회적으로 구조화된 편향성이 내재하고 있어 인공지능 역시 편향된 성능을 보이게 된다는 것이다. 다시 말해, 인공지능 알고리즘은 데이터에서 예측 변인을 설명하는 주요 특징을 도출해 이를 최적화 모델로 추상화해 정보 혹은 행동을 위한 추론을 하는 시스템이기 때문에 데이터가 표상하는 특징이 차별 혹은 불공정성을 유발할 수 있다. 가령, 이미지나 비디오에서 사람을 식별하기 위해 개발되고 있는 안면인식 시스템의 알고리즘은 이목구비의 위치와 모양의 특징을 구분하기 위한 학습으로 얼굴 데이터를 이용하는데 여기에 특정 인종과 성별, 연령의 얼굴이 과대 혹은 과소 포함되어 있다면 편향된 결과가 도출될 수 있다. <그림 3>은 안면인식 시스템이 미국의 오바마 전 대통령의 얼굴을 젊은 백인 남성의 얼굴로 인식한 결과를 통해 데이터의 불균형에 따른 인공지능의 편향성을 지적하고 있다. 즉, 시스템 사용자는 물론 권력을 가진 의사결정권자 누구의 편향적 의도가 개입하지 않아도 인공지능 알고리즘이 편향된 결과를 도출할 수 있다는 것이다. 이것은 빅데이터의 관점에서 개인의 무의식적 행동까지 최대한의 흔적이 수집되며 사회적 산물인 불평등과 차별, 편견이 내재한 데이터가 구성되고 이를 인공지능의 알고리즘이 학습해 개발자나 사용자의 의도와는 무관한 편향이 발생할 수 있음을 의미한다.
자료: @Chicken3gg [Tweet]. https://twitter.com/Chicken3gg
인공지능 편향성의 개선방안
위에서 논의한 인공지능의 편향성은 그 유형별 원인을 고려할 때 어떻게 개선될 수 있을까? 첫째, 개인의 편향성이 인공지능으로 강화되는 경우는 개인의 성향과 이에 대한 맞춤형 서비스로 수익을 창출하는 추천 알고리즘의 속성이 문제의 원인이다. 이에 미디어 리터러시 교육을 통해 콘텐츠 이용자에게 편향 가능성에 대한 비판적 인식을 촉진하고 알고리즘의 사회적 책임을 디지털 플랫폼 기업에게 요구함과 동시에 공영방송과 같은 공공 인터넷 플랫폼의 개발 등의 방안이 해결책이 될 수 있다. 둘째, 권력의 편향성이 인공지능으로 발현되는 경우는 정부 혹은 정당이 주축이 되어 정치적 목적의 선전을 펼치기 위한 알고리즘 활용이 문제의 원인이다. 따라서 저널리즘 차원에서 오히려 알고리즘을 적극 활용해 온라인에서 벌어지는 정치적 선전을 지속적으로 감시하고 인공지능 악용에 대항하는 노력이 필요하다. 또한 소셜미디어 플랫폼 기업들에게 악의적 봇 계정들에 대한 탐지와 제거를 요구하는 제도적 장치를 마련하는 것 역시 개선방안이 될 수 있다.
데이터의 편향성이 인공지능에 반영된 경우는 앞선 두 문제보다 신중한 접근을 요구한다. 왜냐하면 알고리즘 개발자나 사용자의 의도와는 무관하게 편향된 결과가 발생할 수 있기 때문으로 개선의 책임과 노력을 요구할 대상이 불분명한 것이 그 이유다. 사실 이러한 유형의 데이터의 편향은 알고리즘의 설계와 사용의 의도와는 상관없이 발생하는 일명 숨겨진 편향으로 일상의 세밀한 부분까지 포함하는 대단위 데이터를 구축해 인공지능의 예측 성능을 높일수록 현실 세계에 존재하는 사회적 편향이 반영된다는 역설이 존재한다. 즉, 객관적으로 구성된 데이터가 사회적 불균형을 반영하고 있어 이를 학습한 인공지능 역시 편향을 가지게 된다는 것이다. 미국의 강력 범죄자 데이터로 학습시킨 인공지능이 범죄 피의자에 대한 유죄 여부를 판단할 땐 기존 데이터 구성의 다수를 차지하는 흑인 남성에게 불리한 결과를 도출하는 것은 사법 영역에서 발현된 인종에 대한 사회적 편견과 불평등이 인공지능에 의해 재생산된 것이라는 주장(Angwin et al., 2016)은 위의 관점에서 볼 때 일견 타당하다.
숨겨진 편향을 드러내고 감시하기
그렇다면 데이터 문제로 인한 인공지능의 편향성은 어떻게 개선될 수 있을까? 데이터의 편향을 해소하는 방안은 중립적이고 공정하게 데이터의 구성이 전제되어야 하지만, 사실 이 조건을 달성하기 위한 연역적 접근은 간단한 문제가 아니다. 중립적이고 공정하게 구성된 데이터가 정확히 무엇이고 어떻게 수집 가능한 것인지에 대한 일치된 견해가 마련되기 어렵기 때문이다.
반면 데이터의 어떠한 특성이 알고리즘의 편향된 예측 결과에 영향을 미치는지 귀납적으로 검사하고 평가하는 방식이 현실적으로 효과적인 대안이 될 수 있다. 그리고 이를 위해서는 데이터 구성 및 알고리즘 개발에 있어 투명성(transparency)과 설명가능성(explainability)을 요구하는 제도적 장치가 마련되어야 함은 물론이다. 관련 전문가의 주도로 FAT/ML(fairness, accountability and transparency in machine learning) 조직이 출범해 책임성(responsibility), 설명가능성(explainability), 정확성(accuracy), 감사 가능성(auditability), 공정성(fairness)의 5가지 원칙으로 알고리즘 개발과 데이터 구성이 이뤄져야 함을 제시한 것 역시 같은 문제의식의 발로이다(Diakopoulos et al., 2017).
더욱이, 알고리즘 개발자 입장에서는 인공지능 성능의 정확성과 효율성이 중요한 가치이기 때문에 외부의 신뢰할 만한 기관에서 공정성에 대한 평가를 수행할 수 있는 공공기관을 통한 감시 및 기준 체계가 설치될 필요가 있다(정희태 외, 2019). 이러한 필요성에 대한 응답으로서 우리나라의 경우 과학기술정보통신부 주도로 인간중심의 신뢰할 수 있는 인공지능 실현 전략을 세우고 2026년까지 5년간 설명가능하고 공정하며 견고한 인공지능 개발과 검증 및 인증 체계의 마련을 추진한다는 계획을 발표한 바 있다.
더 나아가, 관련 학계 역시 데이터로 인한 알고리즘의 편향성에 대한 관심을 바탕으로 실증분석에 기초한 평가를 위해 지속적인 노력을 기울여야 한다. 가령, 네이버가 악플 탐지를 위해 개발한 인공지능 서비스인 ‘클린봇’의 편향 가능성을 진단하기 위해 악플로 분류된 댓글과 그렇지 않은 댓글을 실증적으로 비교하고 그 대상 집단에 따라 성능 차이가 발생하고 있음을 지적한 연구(이신행, 2021)는 데이터에 숨겨진 편향을 드러내고 이를 개선하기 위한 시도이다.
인공지능의 편향성 문제를 개선하는 방안은 지금까지 논의한 다층적인 노력들이 확립되고 어우러질 때 실현 가능하다. 그리고 그것이 우리가 기대하는 신뢰할 수 있는 공정한 인공지능에 한 발 더 가까워지는 길이 될 것이다.
<참고문헌>
이신행. (2021). 편향적 인공지능: 네이버의 악플 탐지용 인공지능 ‘클린봇’이 판별한 혐오표현의 유형 분석. <사이버커뮤니케이션학보>, 38권 4호, 33-75.
Angwin, J., Larson, J., Mattu, S. and Kirchner, L. (2016.05.23.), ʻMachine bias: There’s software used across the country to predict future criminals. And it’s biased against blacksʼ, ProPublica.
[https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing]
Chen, W., Pacheco, D., Yang, K.-C., & Menczer, F. (2021). Neutral bots probe political bias on social media. Nature Communications, 12(1), 5580. https://doi.org/10.1038/s41467-021-25738-6
Chicken3gg. [@Chicken3gg]. (June 20, 2020). [Tweet]. https://twitter.com/Chicken3gg
Diakopoulos, N. et al. (2017). Principles for accountable algorithms and a social impact statement for algorithms. URL:
https://www.fatml.org/resources/principles-for-accountable-algorithms
Ferrara, E., Chang, H., Chen, E., Muric, G., & Patel, J. (2020). Characterizing social media manipulation in the 2020 U.S. presidential election. First Monday, 25(11). https://doi.org/10.5210/fm.v25i11.11431
Howard, P. N. (2020). Lie machines: How to save democracy from troll armies, deceitful robots, junk news operations, and political operatives. Yale University Press. https://doi.org/10.2307/j.ctv10sm8wg
Woolley, S. C., & Howard, P. N. (2019). Computational propaganda: Political parties, politicians, and political manipulation on social media.
디지털사회(Digital Society)는 연세대학교 디지털사회과학센터(Center for Digital Social Science)에서 발행하는 이슈브리프입니다. 디지털사회의 내용은 저자 개인의 견해이며, 디지털사회과학센터의 공식입장이 아님을 밝힙니다.
쉽게 읽을 수 있어 도움이 되었습니다.
아 노잼